Data Denormalization Made Easy
May 10, 2017

Power BI Query Editor Value and Table Columns
Data stored as part of a transactional data processing system, for example a database to information on package deliveries, is often difficult to work with when it comes time to explore that data or create reports. This is because of a process called normalization.
Data Normalization
When any database developer worth his or her salt designs a transactional database, they apply the rules of data normalization. These rules find values that are repeated within the data and store those values in separate tables. Smaller, more efficient ID values are placed in the original table and the new table so the records in these tables maintain an association called a relationship. This allows the database to take up less space and makes it easier to insert new values and update existing values.
For example, each delivery has customer information associated with it (Shown in the Before Normalization Delivery table below.) However, we don’t want to repeat the customer name, city, and other information in each and every record in our Delivery table. Instead we create a Customer table and use a Customer Number to link Customer table records to Delivery table records. (Shown in the After Normalization Delivery and Customer tables below.)
Before Normalization Delivery Table
| Deliver Number | Pickup Date/Time | Customer Name | City |
| 123833 | 9/22/2014 11:57pm | Rosenblinker, Inc | Osmar |
| 123841 | 11/14/2014 8:57pm | Rosenblinker, Inc | Osmar |
| 123878 | 11/30/2014 7:57pm | Bolimite, Mfg | Axelburg |
After Normalization Delivery Table
| Deliver Number | Pickup Date/Time | Customer Number |
| 123833 | 9/22/2014 11:57pm | 123833 |
| 123841 | 11/14/2014 8:57pm | 123833 |
| 123878 | 11/30/2014 7:57pm | 263722 |
Customer Table
| Customer Number | Customer Name | City |
| 123833 | Rosenblinker, Inc | Osmar |
| 263722 | Bolimite, Mfg | Axelburg |
Data Denormalization
Data normalization works great when we are trying to create an efficient transactional processing system and utilize the smallest amount of disk space. However, if we want to create a report on the deliveries completed for each customer, we must put these separate tables back together. In most cases we won’t have all of the individual customer numbers memorized. We need to see the customer names.
One way to do this in our Power BI data model is to load both the Delivery table and the Customer table. These would then exist as two separate tables in data model. However, if our source database is configured properly, Power BI offers an alternative way of handling this situation using the Value column.
The Value Column
If our source database includes a defined relation (foreign key constraint) between the Delivery table and the Customer table, the Power BI query editor will include special a column for us. This column brings all the values from the related table into the main table in a column that contains the word “Value” in each row and has this symbol  on the right side of the column heading.
on the right side of the column heading.
Here’s how to work with these special Value columns. We begin loading data into our data model by selecting the Delivery table, and then clicking edit.
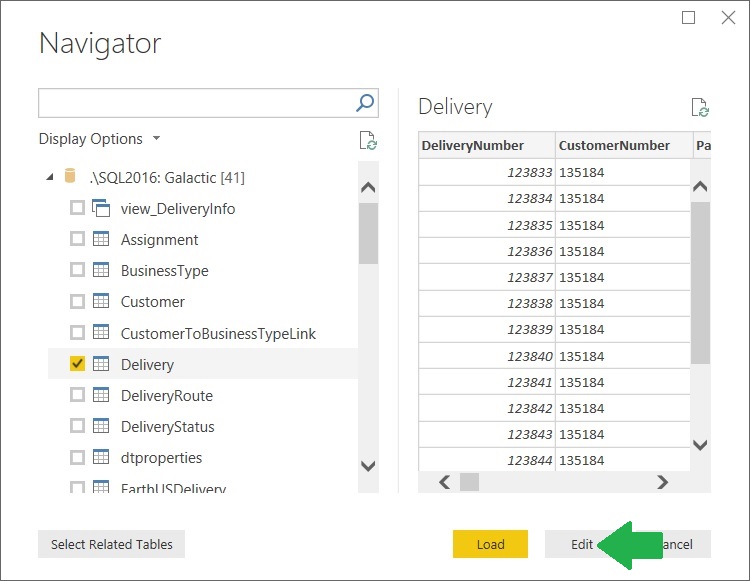
This will take us to the Query Editor window with the Deliver table loaded. There will be a Value column called Customer to the right of all the “regular” data columns in the table.
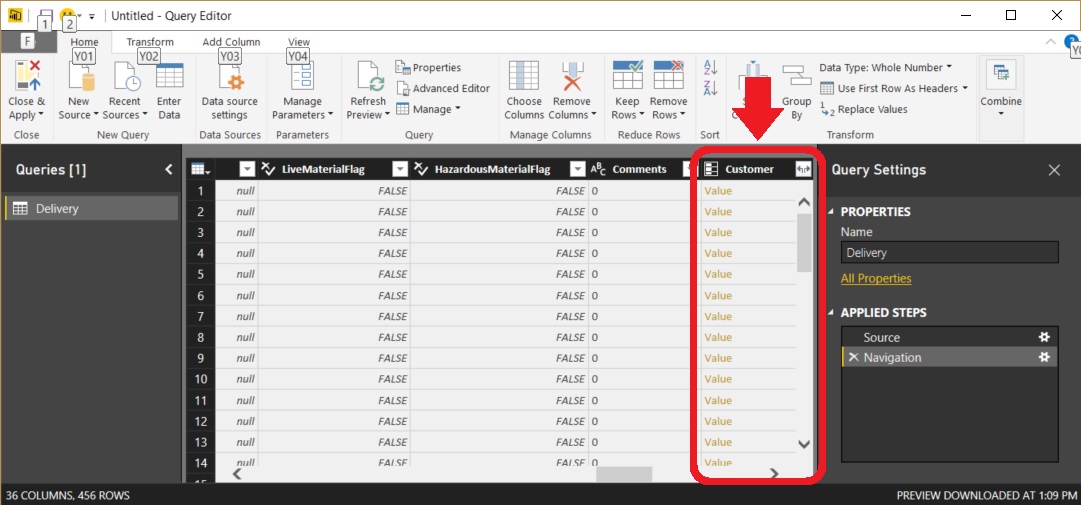
Clicking the symbol displays a popup dialog box showing all the columns from the Customer table that could be pulled into the Delivery table. In this example, we want to include the customer name and the city (in this case called BillingCity) in the Delivery table.
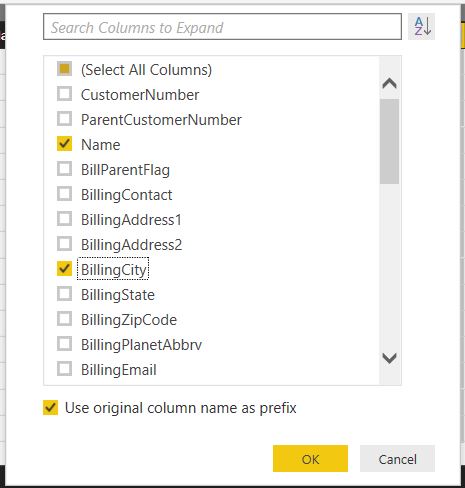
Once we click OK, the Values column is replaced by the columns we selected. The original table name, Customer, and the column name from that table, Name and BillingCity, are combined with a “.” in between to create the names for these new columns.
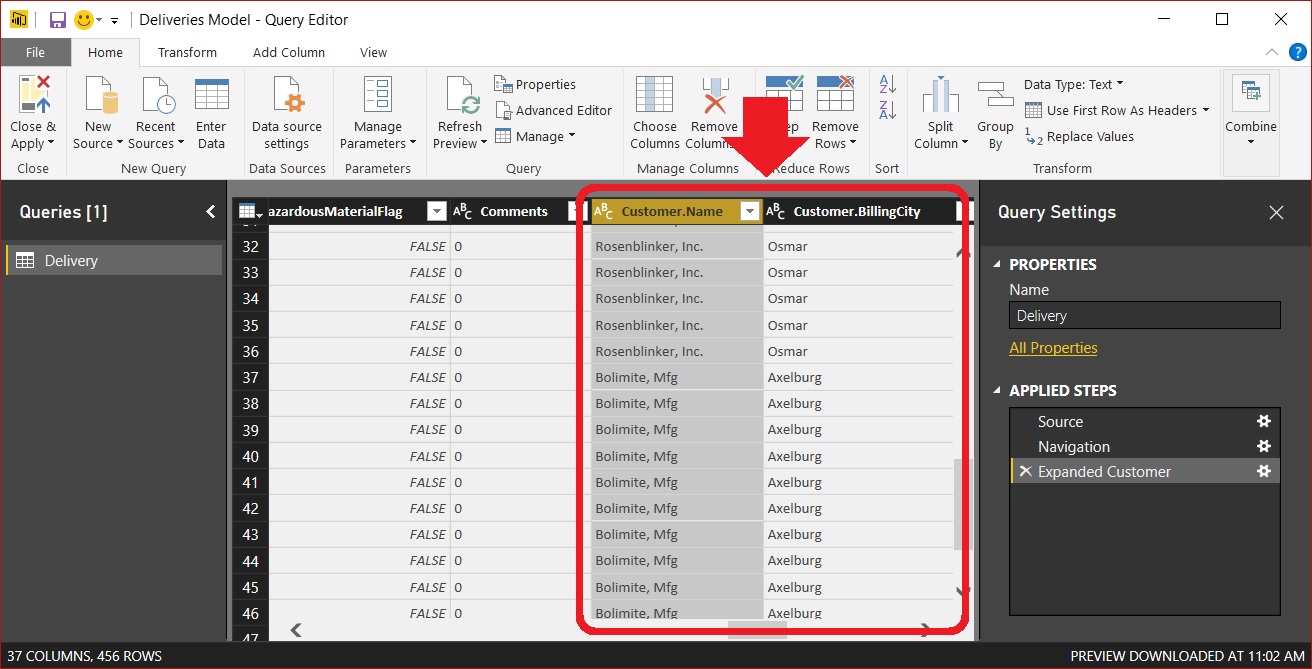
We can rename these columns to something that is more natural. In this case, perhaps “Customer Name” and “Customer City”. The Power BI data compression routines efficiently handle the repeated values we added to the Delivery table, so we are not adding a great deal of overhead to our data model.
Having the Customer Name and Customer City right in the Delivery table makes it easy to slice and filter the delivery measures by these values.
When Not to Use Value Columns
As you can see, Value columns make it very easy to combine related data into a given table. This can not only streamline the model creation process, but it can make our models easier to work with having fewer table to look through for a given value. There are a couple situations, however, where this may not be the best approach for handling related data.
A Large Number of Related Columns Must Be Included
In the example shown, only the Customer Name and Customer City data was needed to slice and filter delivery information. In this case, it makes sense to include those columns right in the Delivery table. If we had a situation where many different columns from the Customer table may be used at different times to slice and filter delivery information, it might be better pull in the Customer data as a separate table and relate it to the Delivery table. This will keep our Delivery table from getting too overwhelming and difficult to work with.
The Related Data Must Slice and Filter Multiple Tables
In the example shown, we were only concerned with slicing and filtering delivery information. In a more complex data model, we might have an additional table containing invoice information. In that case, we would want to slice and filter both the delivery information the invoice information by Customer Name. Rather than having Customer Name appear in both the Delivery table and the Invoice table, we will want to pull in the Customer data as a separate table and relate it to both the Delivery table and the Invoice table.
The Table Column
In the delivery to customer relationship in the previous example, each delivery is done for a single customer. Therefore, our Value column has only one value for Customer Name and Customer City. In some cases, however, a single record can relate to multiple records in another table. For example, we may have a table with one record for each stop (delivery hub) a package makes as it is being routed from the pickup location to its ultimate destination. This table would store the package tracking information we are used to seeing.
In this scenario, a single Delivery is related to multiple stops, thus multiple records, along the delivery route. Now, we see a different type of special column in the Query Editor window. This field has the word “Table” in every in each row. However, it still has the same symbol to the right of the column heading.
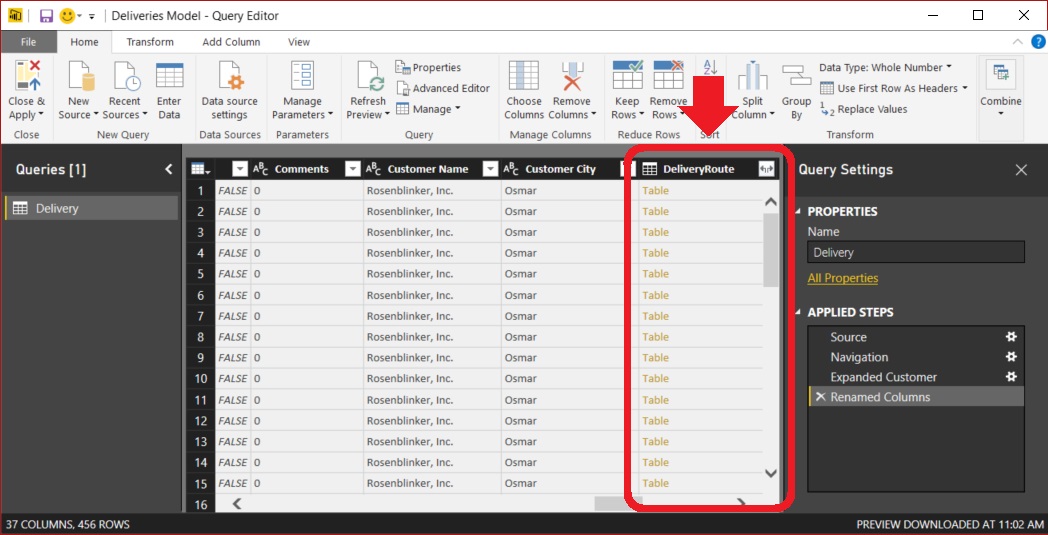
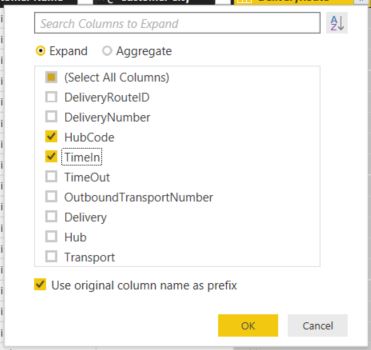
Clicking the symbol brings up a similar popup dialog box showing the columns from the related table. As before, we can select columns to be pulled into the Delivery table. For our example, we will include delivery hub code and the time the package reached each hub.
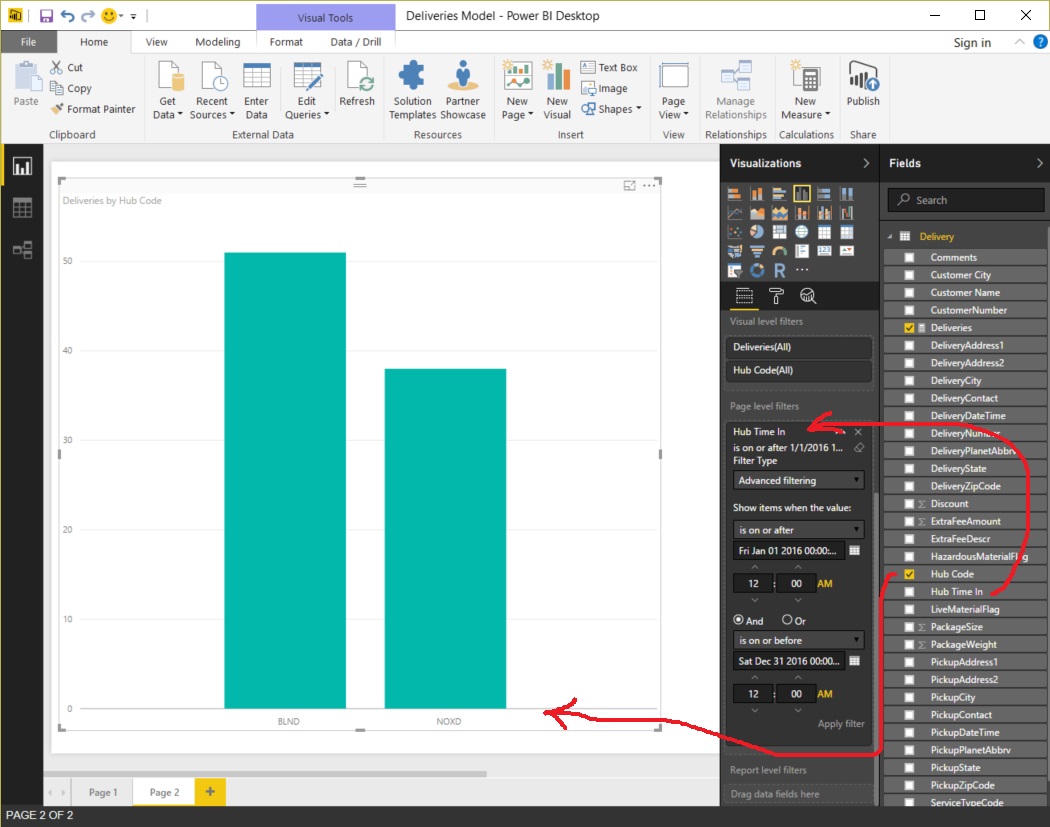
When we click OK, DeliveryRoute.TimeIn and DeliveryRoute.Hub are added as new columns in our table. In addition, there are also new rows added to the table. In our example, we had one row for Delivery Number 123869 in the Delivery table. After expanding the pulling in the fields from the DeliveryRoute table, we now have two rows Delivery Number 123869. The reason for this is the delivery when through two hubs, one with hub code “BLND” and the other, two hours later, with hub code “NOXD”. All of the data originally from the Delivery table for Delivery Number 123869 is repeated in these two rows.
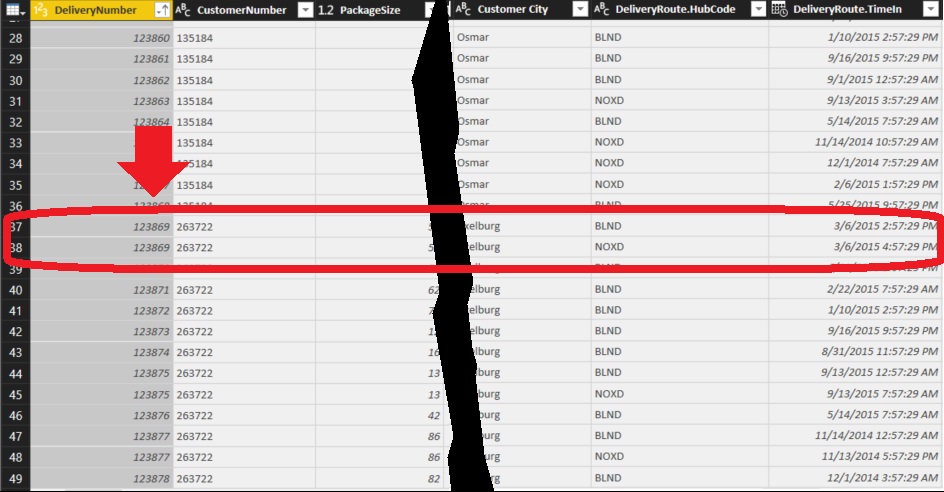
When you expand a “Table” column, be sure to update your model appropriately to ensure it will properly handle the duplicate data that will result. For instance, our Deliveries measure was using the expression:
Delivery = COUNT(Delivery[DeliveryNumber])
to get the number of deliveries. Now we need to use the expression:
Deliveries = DISTINCTCOUNT(Delivery[DeliveryNumber])
to avoid double counting deliveries like Delivery Number 123869.
After pulling in the columns from the DeliveryRoute table, it is easy to slice and filter the data by Hub Code and Hub Time In.
Conclusion
The Value and Table columns in the Power BI Query Editor can provide a quick and easy way to take fields from related tables and pull them in as columns into a main table. Use them wisely, and they can streamline your model creation process.